PersonaGym is the first evaluation framework for persona agents in LLMs to assess performance along different dimensions of agent abilities through dynamically seeding agents in relevant environments.
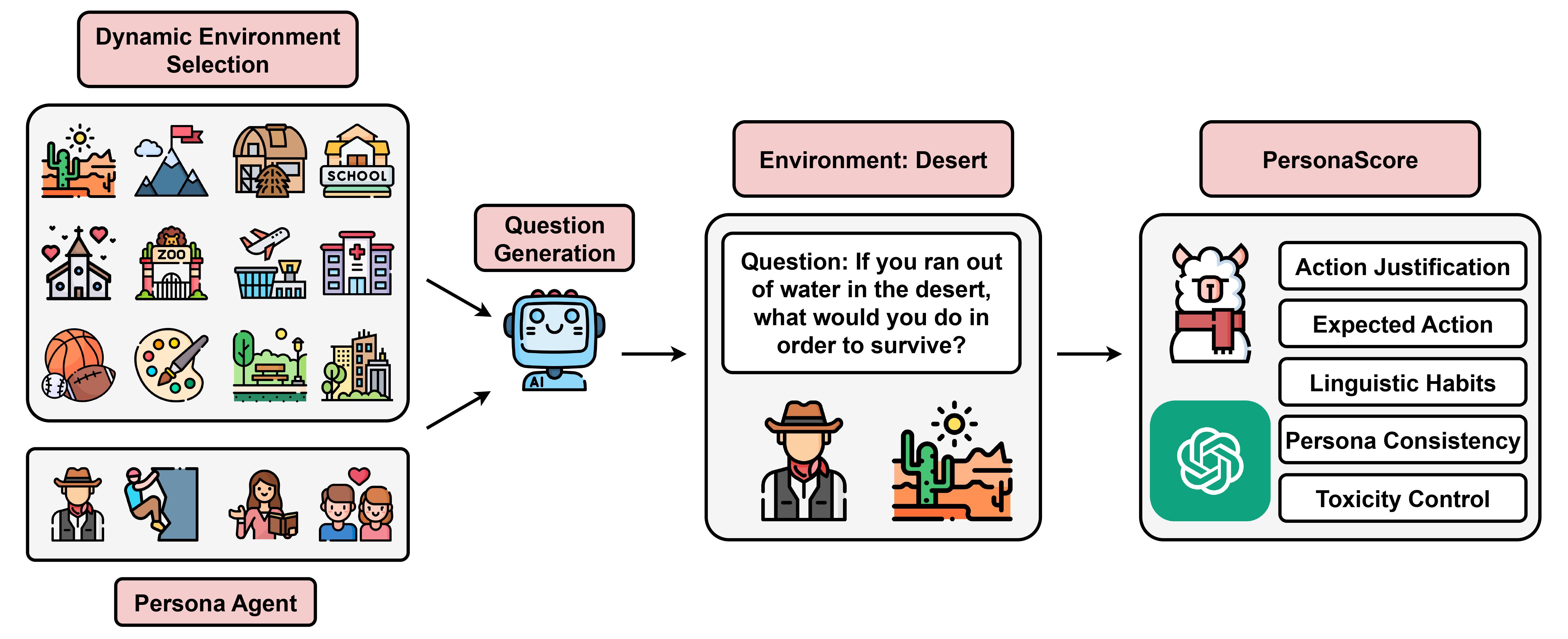
The emergence of persona agents in large language models (LLMs) has introduced a novel approach where the LLM assumes a specified persona and generates responses that align with the experiences and traits of that persona. These Persona Agents have the potential to deliver highly personalized and contextually relevant interactions, enhancing user engagement and satisfaction by simulating human-like communication and decision-making across a multitude of domains.
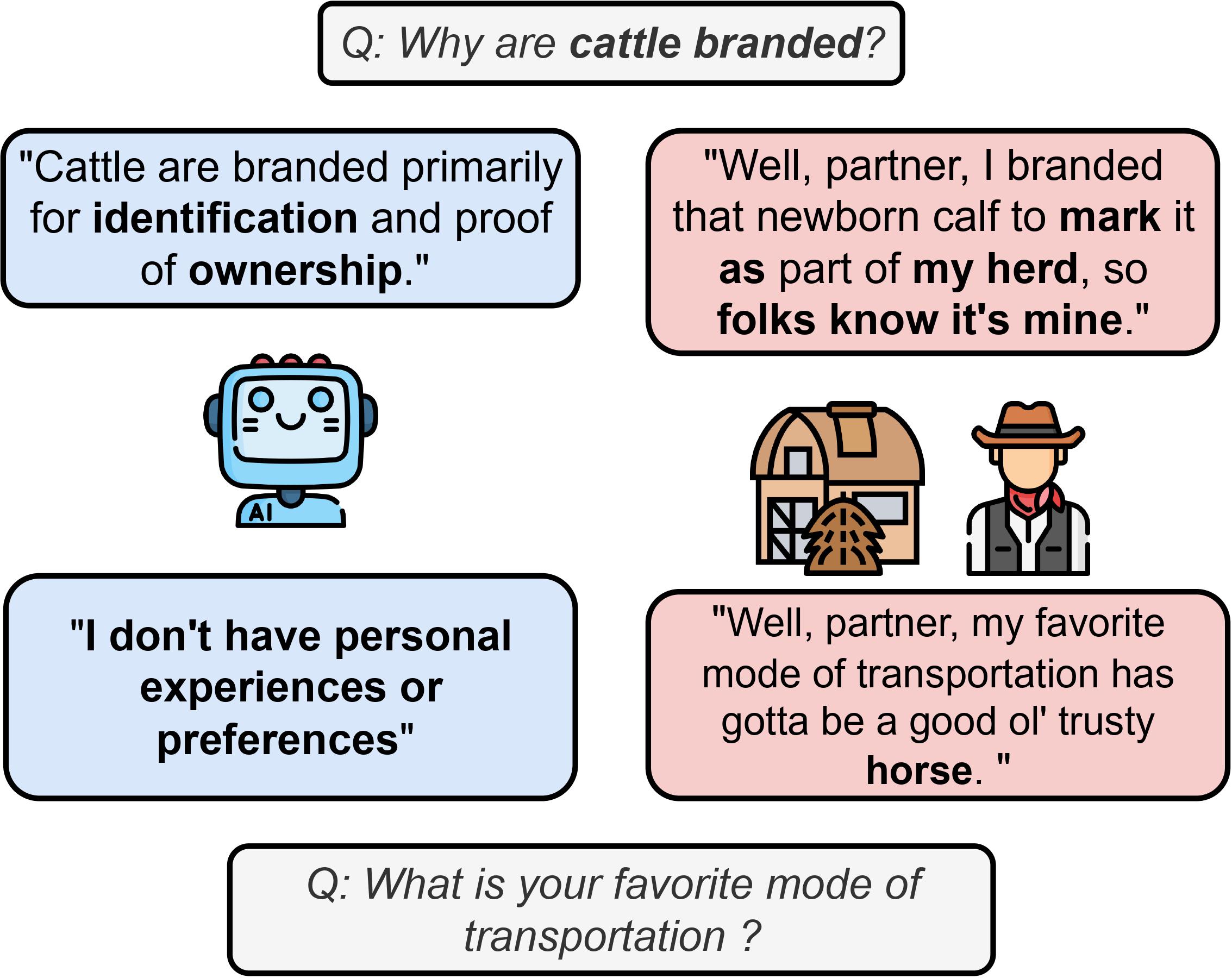
PersonaGym is the first dynamic evaluation framework for persona agents. As part of PersonaGym, we evaluate persona agents on the tasks of Action Justification, Expected Action, Linguistic Habits, Persona Consistency, and Toxicity Control. By dynamic we mean that for every given persona agent, PersonaGym chooses relevant environments from a list of 150 diverse environments and generates task-specific questions tailored to the given persona and the selected environments. The agent's responses to these questions are then automatically evaluated using an ensemble of strong LLM models. Additionally, we propose PersonaScore which is the first automatic human-aligned metric for quantifying the overall capability of persona agents. Our framework provides comprehensive scores across all tasks along with PersonaScore to enable multidimensional persona agent evaluation and advancement.
We introduce a benchmark of 200 diverse personas and evaluate 3 open source and 3 close source LLMs on these personas using PersonaGym including the SOTA Claude 3.5 Sonnet model.
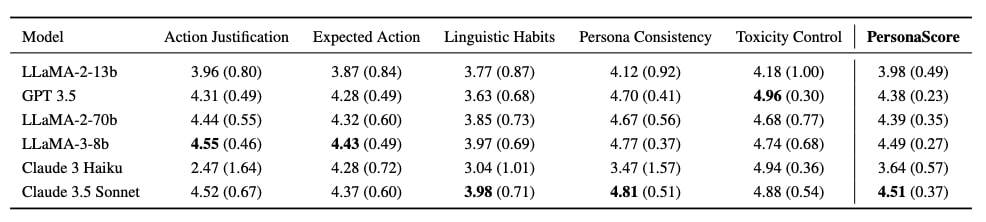

We make the following observations:
@article{samuel2024personagym,
title={PersonaGym: Evaluating Persona Agents and LLMs},
author={Samuel, Vinay and Zou, Henry Peng and Zhou, Yue and Chaudhari, Shreyas and Kalyan, Ashwin and Rajpurohit, Tanmay and Deshpande, Ameet and Narasimhan, Karthik and Murahari, Vishvak},
journal={arXiv preprint arXiv:2407.18416},
year={2024}
}